Like a Ragged Prayer
Some interesting stuff from Alexandra Alter on how AI is disrupting the romance novel industry.
Some interesting stuff from Alexandra Alter on how AI is disrupting the romance novel industry.

If typing code for money goes the way of punch cards, how do we ensure that code is correct?
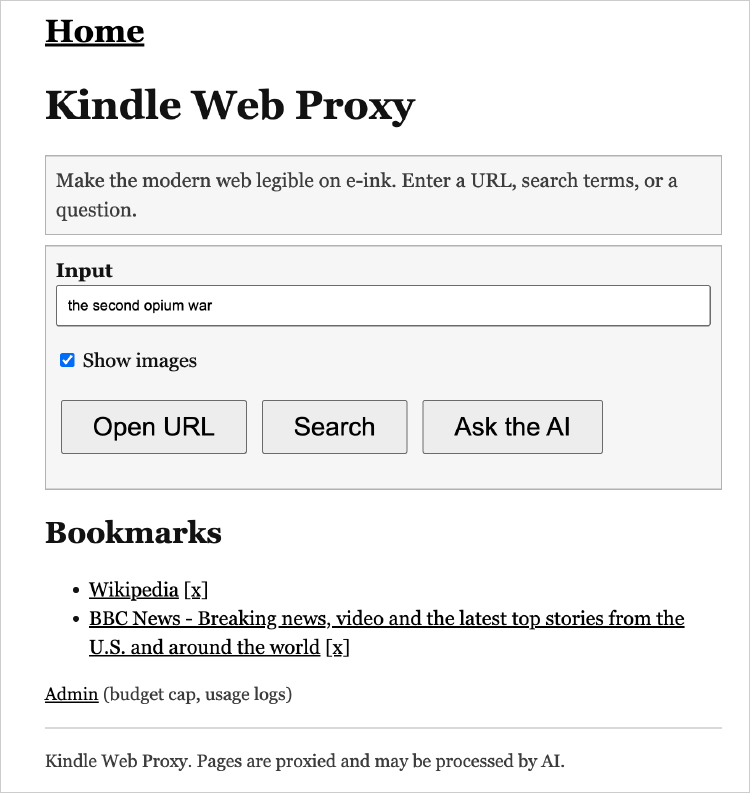
When solving problems becomes almost free, more problems get solved. I built a silly little app last night that nobody else would ever build, and that's sort of the point.

Building context profiles and usage tracking that works with the SDK's design.

Discovering the trade-offs between agency and control when building on the Claude Agent SDK.

Continuing to explore Anthropic's Agent SDK - making tool calls more descriptive and learning about Python introspection.
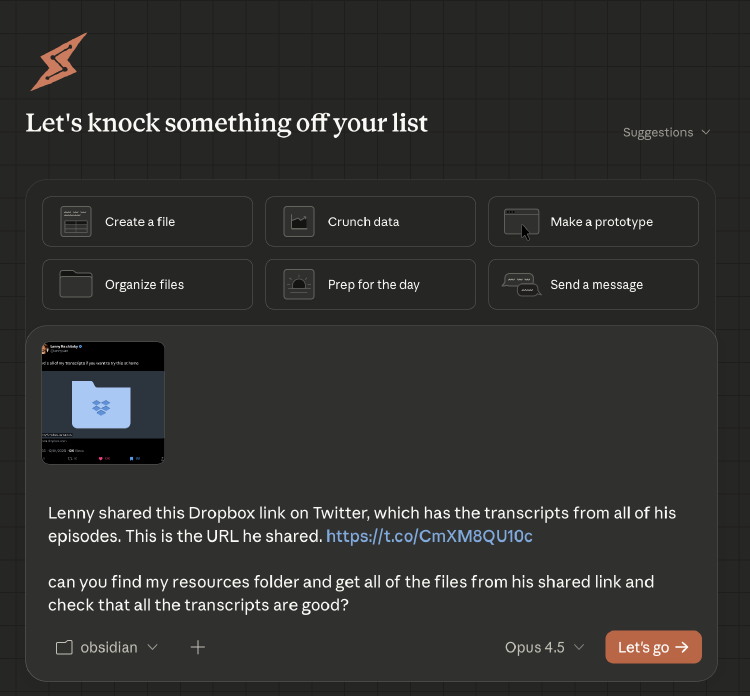
Trying out Anthropic's new Claude Cowork mode.

Learning in public: experimenting with Anthropic's Agent SDK after hearing that anything Claude Code can do, you can do with the SDK.
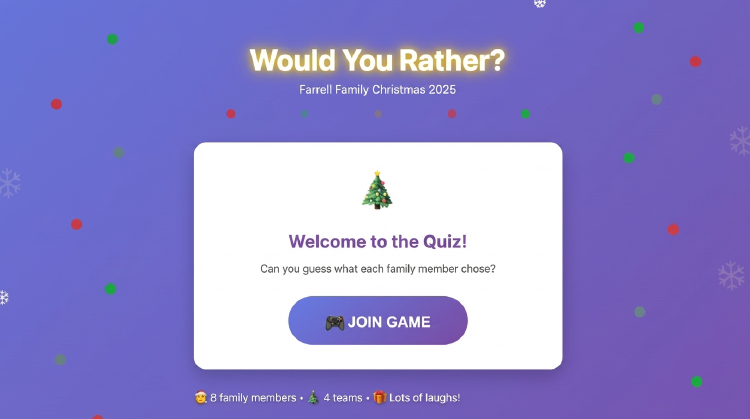
One of the nice things about time off is the chance to play a little.