Open Models in 2024: Progress and Challenges
Open models achieved a lot in 2024, Luca from the AI Institute gives a good overview.

- David Gérouville-Farrell
- 5 min read
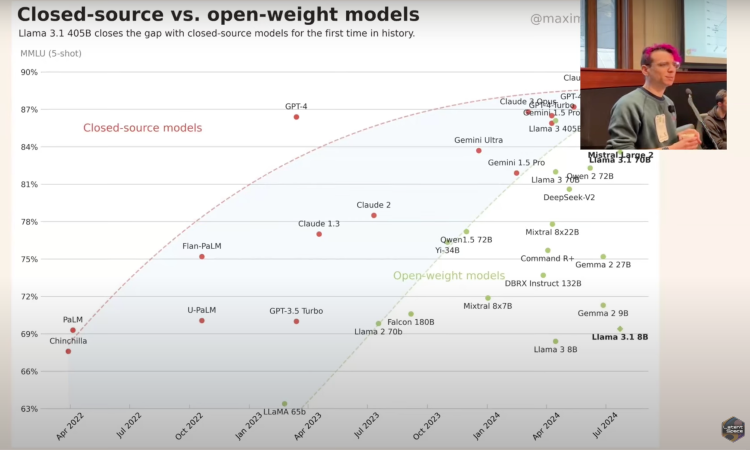
I recently watched a talk from LatentSpace Live (NeurIPS 2024) by Luca Soldaini a research scientist at the AI Institute, on the state of open models in 2024. His reflections on how far we’ve come—and the challenges ahead—offer a good perspective on where (actually-open)AI might be heading.
The Leap Forward
2024 marked a significant shift in open model capabilities. Compared to 2023 (which introduced models like Llama 1 and 2, Mistral, and Falcon), 2024 brought a new class of open models that rival frontier-level closed models. Releases like Qwen, Deep Seek, and Llama 3 show how much ground open-source AI has gained in a relatively short time.
But the leap isn’t just technical. Luca stressed that open models now embrace “recipes”—detailed workflows that document every stage of development, from data gathering to post-training (as oppossed to 2023’s “throw shit at the wall and see what sticks” (paraphrased) approach). This transformation of AI from just sharing “checkpoints” to sharing full pipelines has become a collaboration cornerstone.
Why Open Models Matter
Luca emphasised two big reasons to care:
- Research: The study and scrutiny of large language models—from exploring how they work to evaluating (or even auditing) their biases—only flourish when models are truly open.
- Applied Use Cases: Some use cases demand local models for data privacy, stability, or specialised features like retrieval. In these scenarios, having real control over the model can be more valuable than simply calling a closed model API.
As someone who occassionally works with data that can’t be shared with third parties, I really value the open model eco system and hope it contintues to keep pace with the big labs.
The Compute Divide
One of Luca’s biggest concerns is how only a select few organisations have access to the tens of thousands of GPUs needed for pre-training. This “compute rich club” can afford to train at massive scale, while smaller players are often left fine-tuning existing checkpoints. The upshot? Barriers to entry continue to rise, consolidating power in fewer hands and skewing innovation toward those who are already big.
The Data Crisis
Another challenge—potentially even more pivotal than compute—is shrinking access to high-quality training data. Many site owners have begun blocking AI crawlers, whether intentionally or through blanket policies on services like Cloudflare. Ironically, these blocks might be unknowingly preventing open labs from obtaining data that large closed labs already amassed in prior scrapes. Luca’s warning is stark: “We aren’t just running out of training data—we’re running out of open training data.” If it’s too hard to gather new content, the advantage sticks to those who’ve already done so.
AI aside, this also makes the internet in general more difficult to navigate. Twitter / X is a good example. Compare the innovation being done on Bluesky to the mundanity of X to see what closing access to data can do.
Beyond Tech: Legislative Pressure and Lobbying
Luca highlighted how politics and legislation can profoundly shape the future of open-source AI. For instance, California SB 1047 nearly introduced rules that could have severely restricted open-model releases. The open-source community mobilised just in time to soften it, but the episode underscores that lobbying—though unglamorous—often decides whether open models even remain possible.
He also called out certain fear campaigns that paint open-source AI as an “alien threat” with hypothetical doomsday scenarios like “bio-risk.” According to Luca, these claims frequently overlook existing safety work—for example, AI Institute’s approach to responsible open-model release—and may overshadow more real, concrete AI risks in everyday use.
Open Source AI Definition: Good on Weights, Weak on Data
This year the Open Source Initiative (OSI) introduced its first official definition for “Open Source AI.” On the positive side, model weights must be truly available, and no weird clauses can forbid usage or transformations. But the definition’s stance on data is fuzzy: it only requires that creators provide “sufficiently detailed” instructions for replication—no guarantee the data is actually accessible or affordable to re-collect.
This shortfall frustrates many researchers, who see data as the heart of AI. If we only share a partial pipeline or data instructions that cost tens of millions to follow, how truly open is that?
Fully Open or Bust
Luca went further by defining “fully open” as releasing every ingredient: the code, the logs, intermediate checkpoints, and ideally the data itself. That level of transparency allows other researchers to dissect mistakes, mix in their own enhancements, and genuinely stand on each other’s shoulders. Without it, “open” might become a meaningless label for a partially sealed black box.
Incentives and Sustainability
During the Q&A, someone asked Luca how to align incentives for building open models—especially given the expense and risk. His answer was candid: it’s tricky. Companies often champion “open” because of short-term commercial benefits, but true openness needs consistent, long-term support. Grants, prizes, and community-driven challenges (like FR chol’s ARC prizes) can help, but it’s an uphill battle. When so much capital is required, the philanthropic and research communities must collaborate more deeply to keep this ecosystem thriving.
thingsithinkithink
- The “compute rich club” parallels the consolidation we saw in cloud computing. We might need new models of community-sourced GPU pools or philanthropic labs that share resources.
- Data accessibility is a thornier issue than many appreciate. We can’t rely on assumptions that open data is “out there” unless we actively protect and expand it.
- Safety vs. accessibility can’t be an all-or-nothing choice. The real question is how to manage risk responsibly without outlawing open access.
- Legislative battles might not interest everyday engineers, but they’re fundamental to whether open AI can survive in the long run.
- It’s interesting being in the UK and seeing a kind of tiered access emerging as a consequence of legislation. The states seems kind of like a free for all (as usual) which I don’t love, but being a second tier citizen in the UK is a bit of a pain. And I feel very privileged compared to folks in the EU who can’t even access Llama.
- There’s no putting the genie back in the bottle. And my personal instincts lean toward wanting some regulation to prevent tech running rampant over the rights of creators but now that we are where we are I worry that the UK / Europe will be left behind and productivity fill fall further behind.
- Tags:
- AI
- Open-Source
- Podcast