Error Analysis for Improving LLM Applications
A systematic approach to analysing and improving large language model applications through error analysis.

- David Gérouville-Farrell
- 6 min read

I recently watched a talk by Hamel Husain and Shreya Shankar on error analysis for LLM applications. The approach they presented offers a systematic way to improve AI systems that rely on large language models.
Building LLM applications presents unique challenges since outputs are typically text-based and difficult to evaluate with traditional metrics. While many developers focus on frameworks and tools (which RAG database to use, which agentic framework to implement), Hamel and Shreya emphasise the value of looking at your data closely.
Why Error Analysis Matters
As Greg Brockman, co-founder of OpenAI, tweeted: “Manual inspection of data has probably the highest value-to-prestige ratio of any activity in machine learning.” Hamel goes even further, calling it “the highest ROI activity in machine learning period” and “the highest ROI activity for any AI product, period.”
When you’re building an LLM application, you often find yourself playing whack-a-mole with problems. You notice an issue and fix it with prompt engineering, only to discover you’ve created a new problem elsewhere. Without proper evaluation methods, you lack a coherent strategy for improvement.
Error analysis breaks this cycle by providing:
- Clear priorities for what to measure - Instead of generic metrics, you discover what specifically matters for your application
- Guidance on where to invest your time - Should you tune your RAG system? Refine your prompts? Change your retrieval approach?
The Error Analysis Process
The approach consists of five distinct steps:
1. Annotate
This initial step involves manually reviewing outputs from your system and writing free-form notes about what you observe. It’s crucial not to rush through this stage or outsource it to an LLM.
What makes this stage effective:
- You’re not trying to categorise errors yet
- You’re simply documenting what feels wrong or right
- You don’t need to root-cause issues immediately
- You should spend minutes per example at first
2. Categorise
After collecting your observations, you’ll identify patterns by grouping similar issues. While you could use clustering techniques, LLMs are particularly effective at this stage:
- Feed your notes to an LLM with a prompt like: “I’ve been coding my data to identify things I don’t like in it. Here are the feedbacks I’ve given. Note that this is in order; later feedbacks represent my updated thinking.”
- Ask the LLM to identify common failure modes or suggest categories
- Refine these categories as needed
3. Analyse
With your categories established, you can now quantify how frequently each error occurs. This creates a prioritised list of issues to address and becomes the foundation for targeted metrics.
4. Ship Improvements & Evaluations
Based on your analysis, you can now make targeted improvements to your system and create custom evaluation criteria specific to your application’s needs.
5. Iterate
Return to step one, continuing the process with your improved system.
The Power of Custom Data Tools
One of the most practical takeaways from the talk was the emphasis on building custom data annotation tools. Shreya demonstrated creating a simple data labeling interface in just minutes using this prompt:
I want a custom data labeling interface for me to annotate my outputs of this pipeline. I want there to be a view with a single input/output on the page, maybe the resume on the left and the email in the center, and then an open-ended text feedback box on the right where I can write any failure modes I find in the data. I want there to be some shortcuts. Have left and right hotkeys to quickly iterate through the rows. Have a table of feedbacks persistent, maybe at the bottom right. Generate this app in Flask/HTML. There should be a save/export button to save the feedbacks along with the rows.
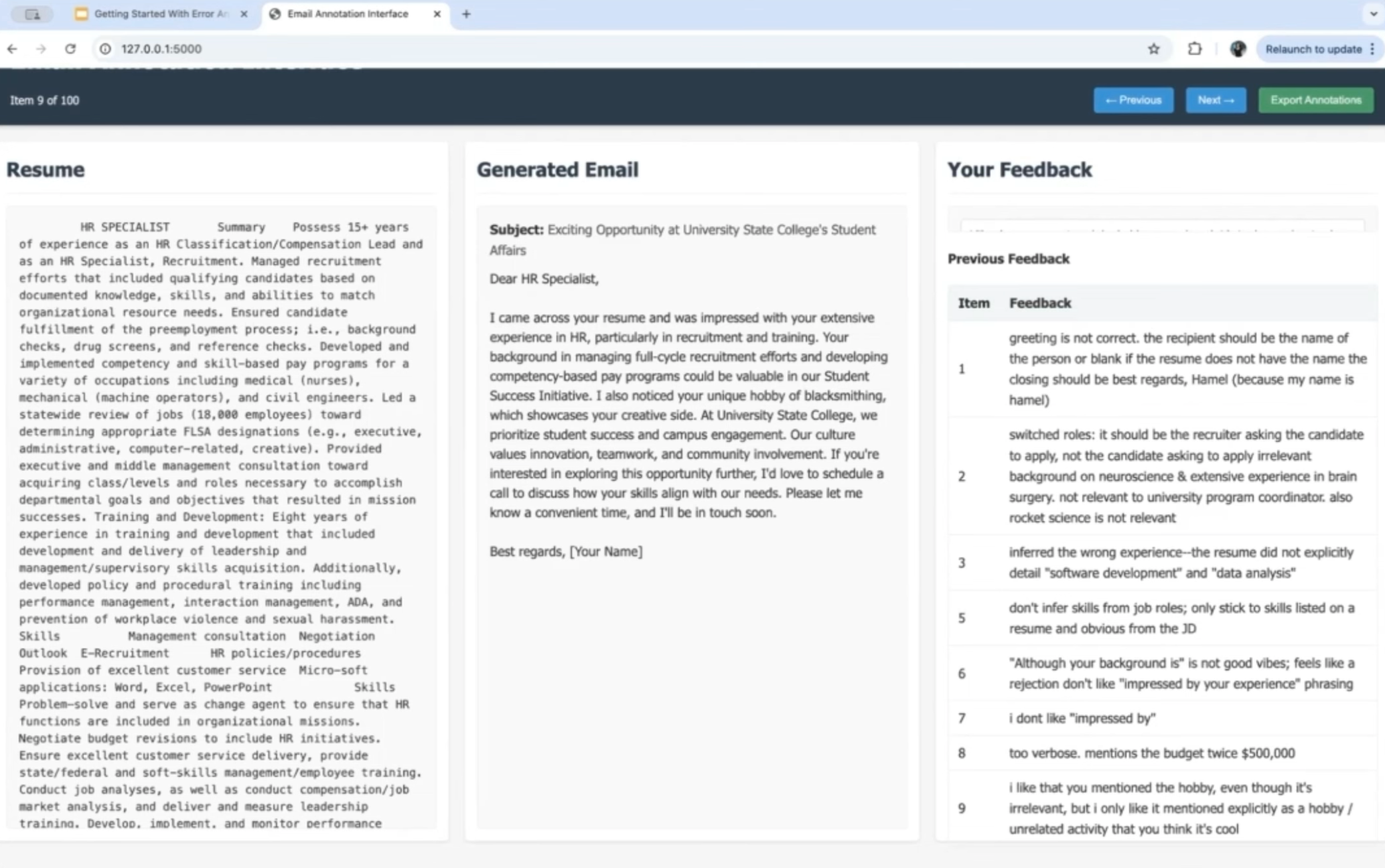
Why is a custom interface so valuable? As Shreya explains, when you view an email in an Excel spreadsheet cell, you have to mentally transform that text into what an email would look like. A dedicated interface eliminates this friction, making it easier to spot problems. I personally have spent days and weeks annotating my data in Excel spreadsheets and Google spreadsheets, and I am completely sold on the custom interface 😵💫
Why You Shouldn’t Jump to LLM Evaluation
When you ask an LLM to judge your application’s outputs without first doing manual analysis, you’ll likely find yourself agreeing with whatever the model says - but missing the specific issues that matter to your use case.
The manual annotation process forces you to articulate what you care about, which creates much more specific and useful evaluation criteria than generic metrics like helpfulness, toxicity, or conciseness scores.
The Case Study: AI Recruiter Emails
To demonstrate the process, Hamel and Shreya worked through a case study of an AI system that writes personalised recruiter emails based on candidate CVs.
ChatGPT is very capable of treating the categories following your bespoke error analysis.

The system showed various issues:
- Misunderstanding the task (writing emails from candidates instead of to them)
- Adding irrelevant background information
- Using phrases like “although your background is…” that create negative impressions
- Being overly verbose
- Using generic, robotic language like “I was impressed by your experience”
By following the error analysis process, they could identify these issues systematically and create targeted improvements to the system.
If you look at those issues, there’s no way that an LLM as a judge would ever have identified them as problems - especially not out of the box without specific guidance. This is a concrete demonstration of the value of manual error analysis. Each LLM product introduces its own types of stochastic issues that are completely bespoke to that application, so we have to tailor our evals to our goals, to our LLM choices, and to our data. There’s no shortcut around it. Once you have this analysis, you can turn it into a scaffold that an LLM can use to evaluate your dataset, but this guidance has to be created the hard way.
thingsithinkithink
-
The friction of working with data in Excel or Google Sheets is something I experienced firsthand. I spent a lot of time with data in my previous project and shipped something successful, but it worked because of effort rather than because I had a really effective process.
-
This approach mirrors qualitative research methods from social sciences. The process of “coding” data (adding interpretive labels) and then finding patterns is a proven technique for making sense of complex, unstructured information. For bonus points, have a second independent person code the error analysis and put your results together. This is how it would be done in social science, but to be honest it’s probably unnecessary here.
-
While traditional metrics like F1 score have their place, I agree with Hamel that bespoke metrics derived from error analysis can be much more information-dense and actionable. On a previous project, I was in a debate with an engineer about the value of F1 score—it may tell you something about your product’s quality, but it doesn’t tell you anything about what to do next.
-
The recommendation to use your own eyes before involving an LLM as a judge resonates with me. LLMs are amazing at understanding natural language, but the ambiguity in our communication creates gaps where the most important insights often hide. (See also: every VIBE-coded project beyond low complexity.)