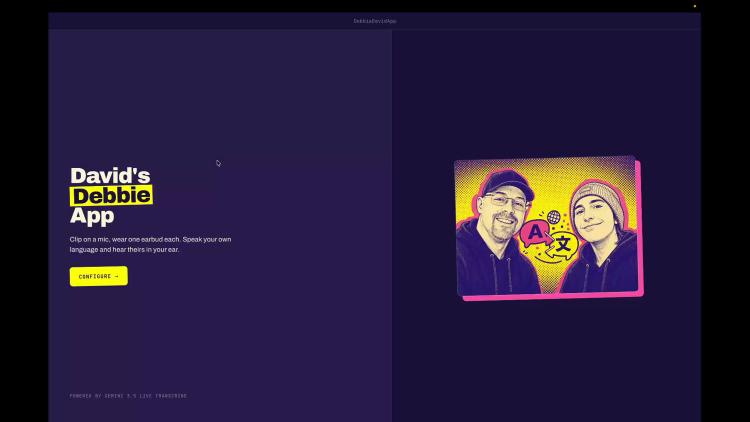
David's Debbie App
Another little bespoke app I built for myself - this one translates English and German live so I can talk to my sister-in-law.

Another little bespoke app I built for myself - this one translates English and German live so I can talk to my sister-in-law.

I gave a talk at AI Practitioner London on what 'good enough' looks like when you can no longer review every line an AI writes.

Ethan Mollick on embedding AI builders alongside subject-matter experts - and why, as someone who has been doing this, I have mixed feelings about it.

Notes from lesson 2 of Hamel and Shreya's LLM evaluation course - covering error analysis, open and axial coding, and systematic approaches to understanding where AI systems fail.
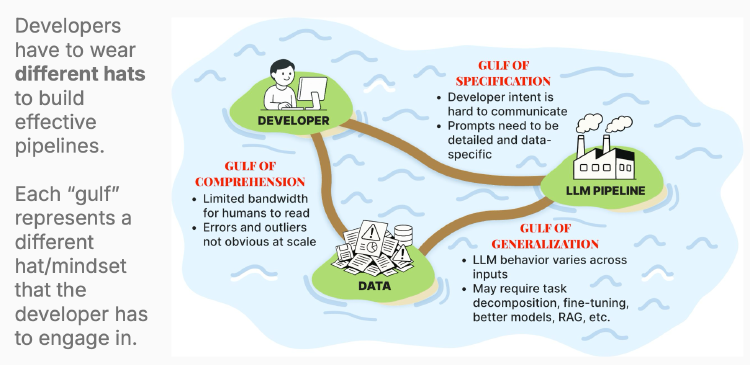
Notes from the first lesson of Parlance Lab's Maven course on evaluating LLM applications - covering the Three Gulfs model and why eval is where most people get stuck.
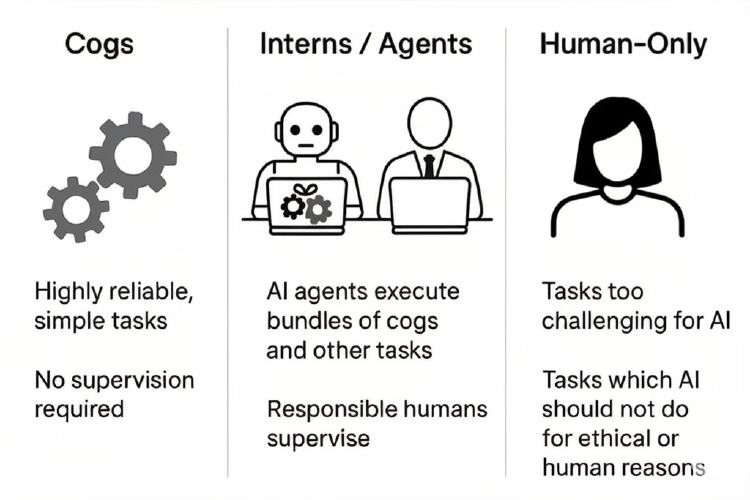
Trying to blend together two AI Framework styling into one that's more practically useful

I like bits of Brunig's and Mollick's AI frameworks, but neither quite works for me.

A systematic approach to analysing and improving large language model applications through error analysis.
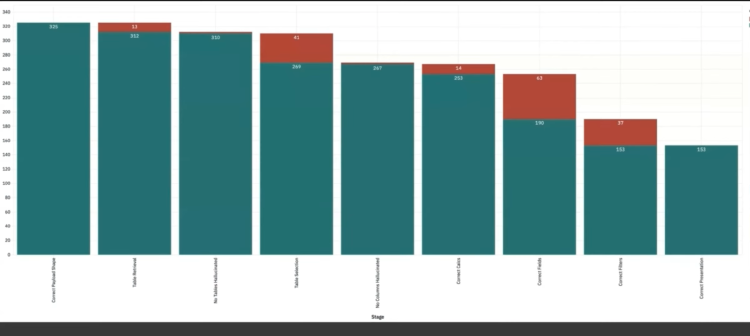
Why evaluation-driven experimentation creates better roadmaps in AI products.