LLM Evals Course Lesson 6: Complex Pipelines and CI/CD
Notes from lesson 6 of Hamel and Shreya's LLM evaluation course - debugging agentic systems, handling complex data modalities, and implementing CI/CD for production LLM applications.

- David Gérouville-Farrell
- 15 min read
The sixth lesson of Hamel Husain and Shreya Shankar’s LLM evaluation course wrapped up unfinished material from lesson 5 (evaluating complex architectures like RAG systems and tool calling) before moving into production concerns. We covered debugging agentic pipelines, handling complex data modalities, and implementing CI/CD for LLM applications.
Debugging Multi-Step and Agentic Pipelines
Complex agentic applications have specific kinds of debugging challenges. You don’t know where to begin with error analysis when you have no idea what your agent is doing. It’s calling tools, invoking functions, making plans - and you need to figure out where to focus your efforts.
The main challenge with agents is error cascading. When an agent makes a mistake early in the process, that error propagates through subsequent steps, obscuring the root cause. By the time you detect the problem, you’re looking at symptoms rather than sources.
This is why comprehensive tracing matters. It doesn’t get rid of the problem, but it gives you the raw material that you can then analyse to actually figure out what’s going on.
Log everything: inputs, LLM thoughts and reasoning, tool calls with their arguments and responses, decisions made, and final outputs. Without this traceability, debugging becomes guesswork.
The Transition Failure Matrix
To make sense of agent failures, Shreya uses a transition failure matrix. During error analysis, you identify the first state in a failed trace where something went wrong. The matrix captures transitions: what was the last successful state, and what was the first failure state?

I hadn’t used a transition matrix before and it took me a second to figure out what it was actually showing. The states appear both as column headers across the top and as row labels down the side. At each intersection, you see the count of failures when transitioning from the row state to the column state. This creates a heat map where you can immediately spot the most problematic state transitions. Since agentic systems don’t give you tight control over their execution flow, it’s difficult to anticipate which state transitions will cause the biggest problems. The transition matrix reveals these patterns at a glance.
The matrix is structured as:
- Rows: Last successful state (the “from” state)
- Columns: First failure state (the “to” state)
- Cell values: Count of failures at that transition
For example, in Shreya’s diagram, the biggest hotspot showed 12 failures when transitioning from generating SQL to executing SQL. This makes sense - if the agent generates wrong arguments, execution will fail.
The matrix doesn’t finish the analysis for you, but it shows you where to look. It transforms the overwhelming complexity of debugging an agentic system into a focused set of problems you can actually tackle.
You can add complexity to this visualisation - ordering rows and columns by priority, creating drill-down views, or using heat maps that sum across columns to identify the biggest problem areas (like “execute SQL” being the biggest issue with 12 total failures).
Failure Funnels for Linear Workflows
When your workflow is relatively linear - like a text-to-SQL pipeline where you retrieve tables, generate SQL, then execute - a waterfall diagram can be more informative than a transition matrix. The failure funnel approach (I’ve written about these here) shows success rates through each stage of the pipeline, visualising how many errors occur at each step. You’re looking to try to get a little bit of pressure to fix issues as far to the left as you can, because detecting an error early on might remove the errors later on. But it only really works in a left-right fashion when your pipeline isn’t supra-agentic.
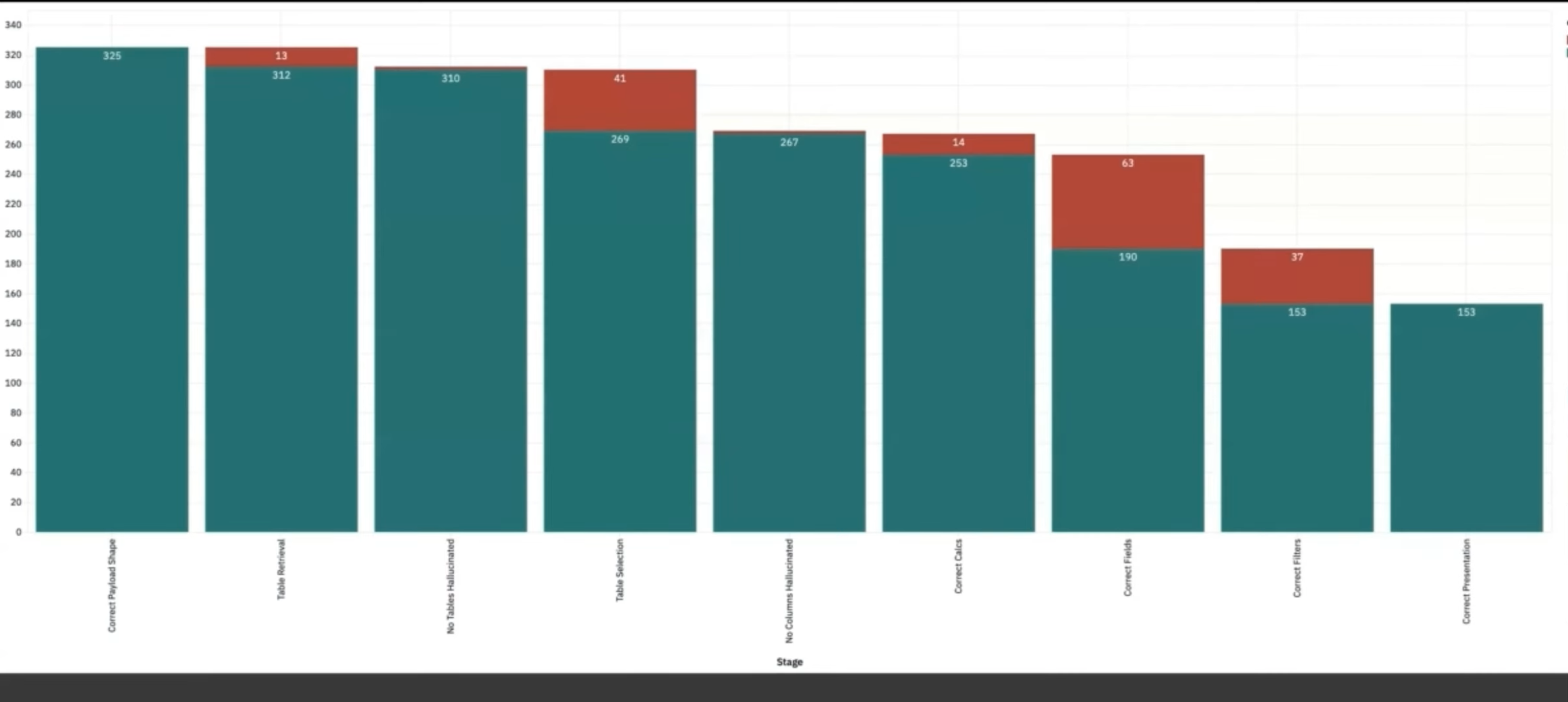
This works well for mostly linear sequences where tool calls have a specified order. The waterfall shows from left to right the sequence of events and how many errors you get at each stage.
Complex Data Modalities
If your system uses complex data types or non-standard variations, for example, really long documents, PDFs, etc., then you’ll need to look out for some specific things when you’re evaluating it.
Images
When processing images with vision-language models (VLMs), error analysis focuses on different failure modes:
Understanding and Description failures:
- Spatial reasoning errors - misjudging positions (left/right, above/below)
- Counting object inaccuracies
- OCR text recognition errors
- Hallucinations - seeing objects or details not present in the image
Generation failures (for text-to-image models):
- Complex composition errors - difficulty with exact counts or distinct identities (“three distinct presidents”)
- Adherence to global constraints
- Inversions - the classic problem where asking for “a room without an elephant” produces an elephant
Basically, you’re doing the same things you would always do when evaluating an LLM-based product, but because you are either interpreting images or generating images, you have different failure modes and you need to be looking for them accordingly.
Long Documents
Long documents aren’t just “more text”. Accuracy often degrades with context length, even when you’re within the model’s stated limits. This connects to something Kwindla Kramer mentioned in my voice agents post - in long multi-turn conversations, tool calls and similar capabilities start to significantly underperform. You’re essentially going out of distribution.
Shreya describes two types of tasks with long documents:
Constant output tasks (needle-in-a-haystack): The output size stays roughly the same regardless of document length. Examples include extracting the thesis of a paper or finding a specific fact. Papers could be tens or hundreds of pages long, but there’s only one thesis. The challenge here is “lost in the middle” - the model struggles when relevant information is buried deep in the context. Foundation model evaluation companies have focused on optimising for this - ensuring LLMs can reliably retrieve needles even when they’re in the middle of the document.
Variable-size output tasks: The output detail scales with document length. Examples include “extract all entities” or “summarise every section”. If a paper is longer, you have more sections, and the complexity of the output increases. These tasks often require chunking strategies where you apply the LLM to each chunk separately.

LLMs in general handle constant output tasks well, but they don’t do well with variable-size output tasks. Many people fall into the trap of thinking “my document fits in the context, so the LLM should handle it” - but if your task is variable-size output, the LLM isn’t very good at being exhaustive or thorough.
I think there’s something deeper happening here than just a long document problem. This is really an LLM capability problem. LLMs aren’t naturally thorough or systematic - they’re System 1 thinkers, not System 2 processors.
Consider what these variable-size tasks actually require. If you’re extracting all logical fallacies from presidential debates, you need the LLM to systematically work through the entire document. The fact that an LLM might be able to find all such instances on a short document is somewhat accidental - they just happen to work when the scope is small enough. The problem isn’t that long documents break them; it’s that these tasks inherently don’t match what autoregressive language models do well.
If you want an LLM to methodically find every single X, you need to build a process that handles the methodical part. Shreya suggests you can experiment to find the Goldilocks chunk size that gives better results. But I kind of feel like each of these types of challenges would require its own bespoke response. For example, if you want to find every single logical fallacy, there probably isn’t one chunk size - you probably have to have paragraph level chunks, but you probably also have to have versions where you look at the whole document or each section of the document, i.e., each theme of the talk as well as the whole talk, because one logical fallacy might not be fully evident in that individual paragraph level. It may only be evident when you look at the argument as a whole. And therefore I think the issue here is less around, as Shreya calls it, variable size tasks. I think it’s around more the idea that LLMs are good at System 1 type tasks and not good at System 2 type tasks.
If you wanted an LLM to find every instance of the word “horse” in a book, the right way to do that isn’t to have lots of small chunks and pass them all to an LLM. The right way to do that is to not use an LLM to do that, but rather to have a system in place that can use a different method, i.e. a string search to find instances of the word “horse”. If you want to, with an LLM system, count how many customers you have, the right way to do that isn’t to show the LLM system all of your customers and ask it to count. It’s to give the LLM system access to tools that can query a database. And if the type of question you’re asking can only be done with an LLM, for example, this fallacies one, then you need to construct a tool that uses an LLM as part of its process, but still provides the thorough, rigorous, methodical scaffold required to be able to answer such questions.
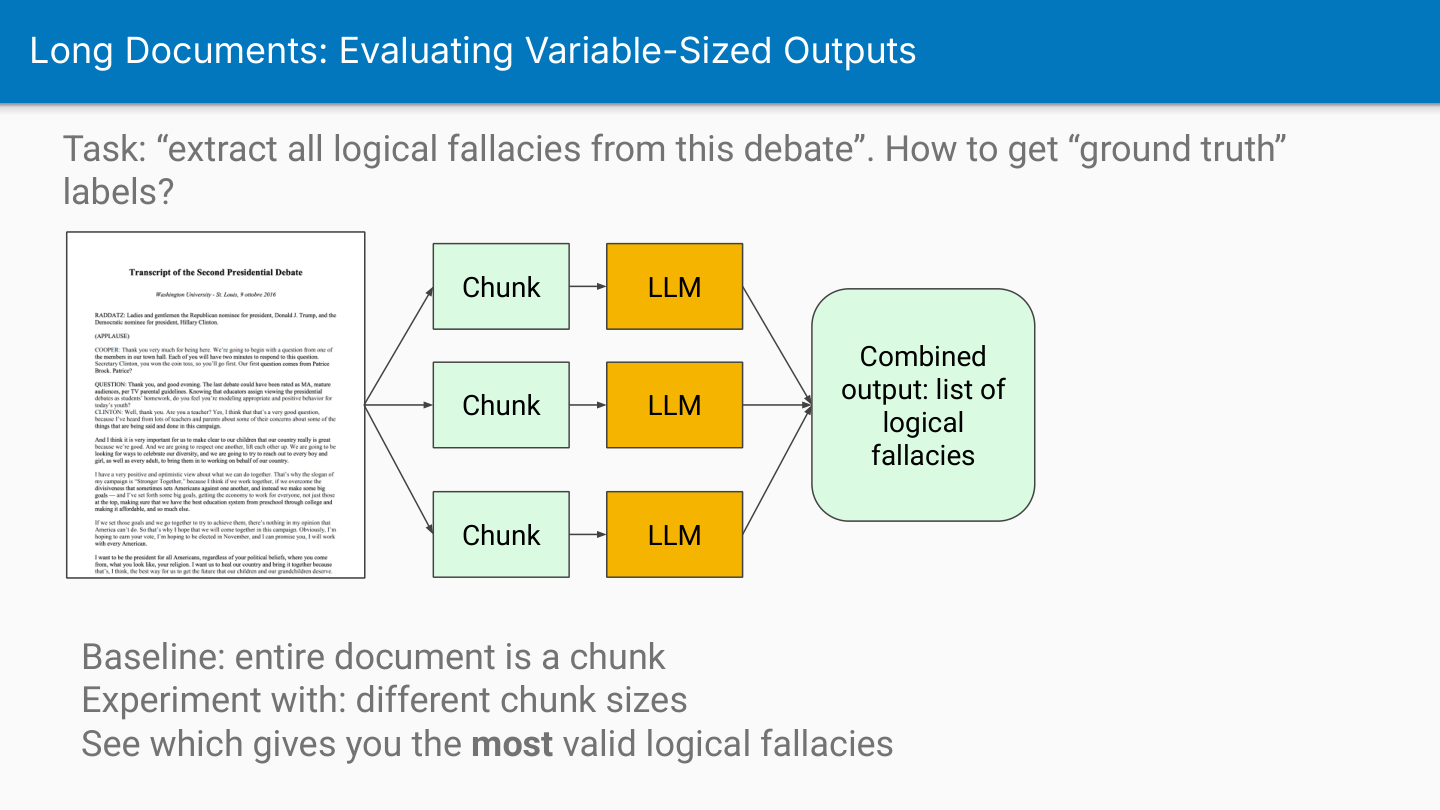
PDFs
PDFs present a specific challenge because you need extraction before the LLM can process anything.
During evaluation, isolate extraction failures from LLM processing errors. People often build their entire pipeline and only discover much later that failures stem from PDF extraction, which feels like wasted effort.
You might be naively blaming the LLM part of your pipeline when actually it’s the OCR part that is failing on you. I liked that Shreya separates the OCR extraction phase from the LLM interpretation of the content phase. That said, more modern LLMs like the Gemini series perform a PDF to image to OCR pipeline under the hood, behind the scenes, abstracted away from you. So it might not always be possible to isolate these extraction failures from processing errors.
Shreya mentioned some tools: Dockling (open source), LlamaParse (closed source), and Azure Document Intelligence if you have Azure credits. The tools in this space keep improving rapidly.

This summary slide captures the key points around evaluating tool calling, debugging multi-step pipelines, and handling different input modalities.
CI/CD for LLMs
After all the work we’ve covered - building LLM-as-judge evaluators, creating methods to measure your system against golden datasets, understanding how your system performs - the question becomes: how do you actually put this into practice in production? That’s where continuous integration and continuous deployment comes in.

The lesson frames this interestingly. The CI part doesn’t feel particularly novel to me - it’s essentially regression testing for LLM applications. You’ve got deterministic checks (did the system select the right tool?) and LLM-as-judge evaluations (is the output quality acceptable?). Even though LLM-as-judge isn’t 100% accurate, you’re treating it as a test, which feels similar to traditional CI regression tests.
The more interesting framing is around CD - continuous deployment. They position this as tracking the “unknown unknowns” versus CI’s “known unknowns.” CI guards against past failures you’ve already identified, while CD surfaces new production issues you haven’t seen before. That distinction is genuinely useful.
The Golden Dataset
Shreya outlines a standard CI process built around a hand-curated golden dataset of inputs with reference outputs. This should include core features, instances of past failures (regression tests), challenging edge cases, and examples exercising different pipeline paths (tool calls, RAG, etc.). She recommends around 100 examples.
But here’s the thing: if you’ve been following the course methodology, you already have this dataset. Through all the error analysis, failure mode identification, and iterative improvement work, you’ve been building exactly what you need for CI. The challenging edge cases, the past failures, the diverse pipeline paths - it’s all the same work you’ve been doing to understand your system.
I’d consider the entire golden dataset as one comprehensive regression test. It’s the hard-earned quality dataset that ensures you don’t accidentally break anything when making changes. The instances of past failures are explicitly regression tests, but even the edge cases and pipeline path examples serve the same purpose - catching regressions in areas you’ve identified as important.
Common CI Mistakes
Shreya highlights two key mistakes. First, assuming that offline CI accuracy predicts production performance. Your golden dataset can’t be representative of real live traffic, so CI pass rates indicate stability against known issues, not overall generalisability.
Second, data leakage. If you include golden set examples in your few-shot prompts, you’ll get artificially high performance regardless of your system’s actual quality - you’ve essentially given the model the answers. Both are standard pitfalls to avoid.
Monitoring Tools Overview
Hamel provides a whirlwind tour of evaluation tools: Braintrust, Phoenix, LangSmith. They’re all broadly equivalent - pick based on your specific needs rather than feature differences.
One student of the course (Alex) shared a useful naming conventions table for LLM tracing tools.
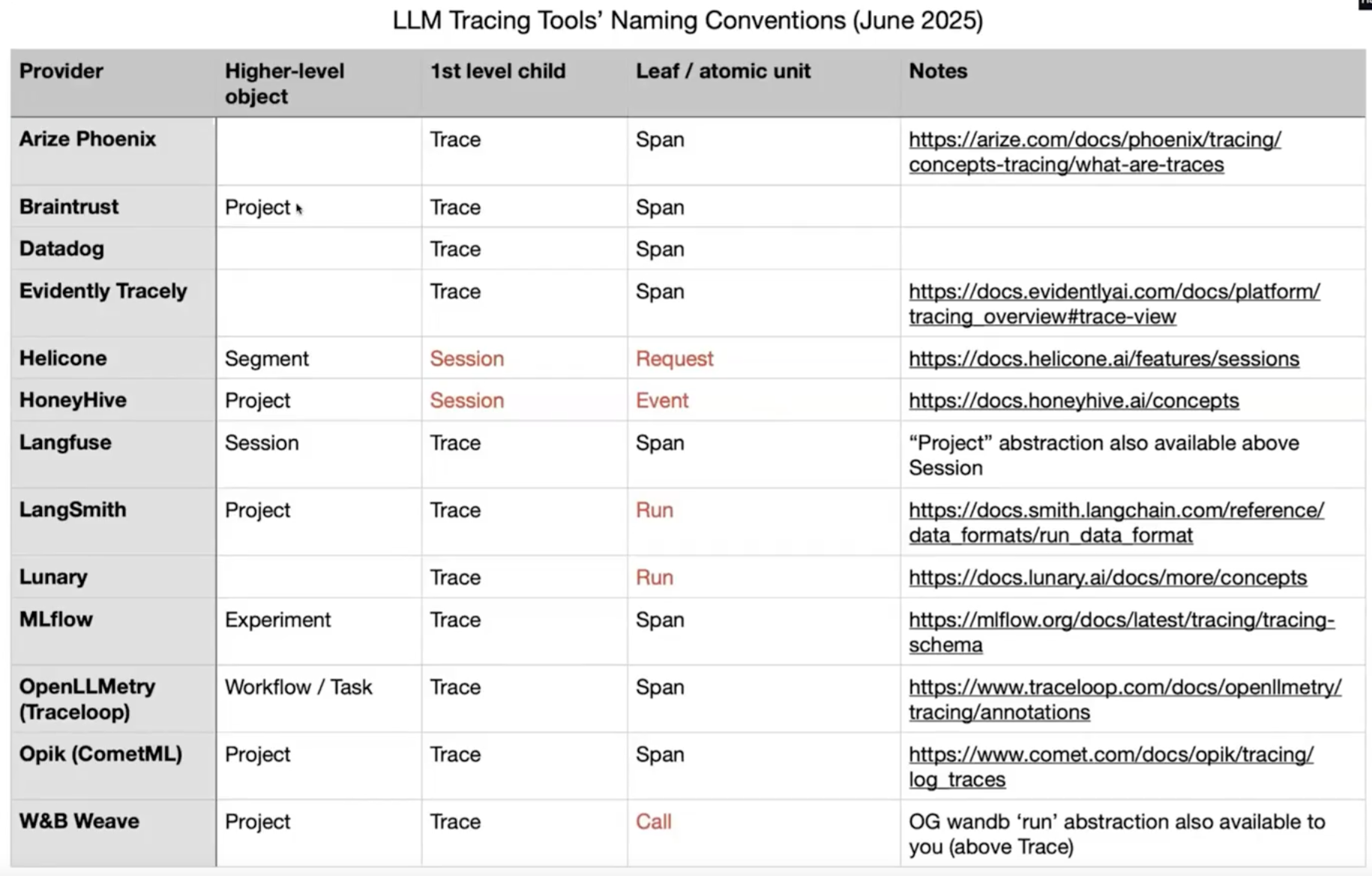
All these tools work with traces and spans. Typically a span is more the atomic unit of a specific turn of a conversation, and a trace is all the turns of the conversation generally. Other vendors have different conventions, which can be confusing, but that’s the general idea.
Key features across all platforms:
Trace viewers: Filter and examine complete interaction logs, including LLM calls, tool invocations, system prompts, and responses. Metadata describes your data - extra information used for filtering and analysis. In BrainTrust’s case with NurtureBoss, you can see different turns of the conversation, an LLM turn with system prompt, then user input, maybe tool calls, and so forth.
Annotation interfaces: Use hotkeys to navigate traces and add labels. BrainTrust lets you hit ‘R’ to start taking notes for open coding. You can configure binary scores or other evaluation criteria. Use left and right arrow keys to navigate between traces.
Prompt playgrounds: Write and compare prompts with templated inputs. You can have a dataset with different inputs you want to template in. Hamel personally doesn’t use these because he finds them constraining as a developer and prefers notebooks. However, they can be useful for domain experts or quick experimentation. Different prompt playgrounds have different capabilities - BrainTrust lets you define custom scores and write code to create LLM-as-judge evaluators directly in the playground (though Hamel still prefers his developer environment).
Datasets and experiments: Save curated traces as golden datasets. You might store your validation and test sets here. Run evaluators against these datasets and track metrics over time. You can run reference-based evaluations, code-based evaluations, or assertions, then store your experiment results and metrics in these tools.
For those wanting to integrate Phoenix specifically, Isaac Flath created a video walkthrough with code examples showing how to add Phoenix tracing to your LLM applications.
Which Tool to Choose?
They’re all basically pretty good, they have some specific characteristics that might make them more suitable for various projects:
- Phoenix: Open source with a strong Python API - choose this if you need self-hosted
- LangSmith: Best if you’re already using LangChain - integration comes out of the box
- BrainTrust: Strong UX if that matters to your team
Operationalising Evaluations (Continuous Deployment)
The CD part focuses on operationalising evaluations during live monitoring through two approaches: async evals for accuracy estimation and guardrails for real-time failure blocking.
The async eval concept is clever. You collect traces from live deployment, then run your judges (deterministic or LLM-as-judge) over that data to estimate failure rates. You don’t have ground truth, so you’re making educated guesses, but if you see consistent failure estimates in one part of your pipeline, it tells you where to focus your attention. This becomes part of your ongoing iterative improvement loop.
You can also use these same judges to detect failure modes and route users accordingly. It’s a systematic approach to monitoring that I hadn’t fully considered before.
Async Evals
Shreya typically runs 5-7 key evaluators in production, mixing code-based and LLM-as-judge approaches. She evaluates a small stratified sample (1-5%) asynchronously due to LLM cost and latency. This can be run as nightly batch jobs or collected and processed periodically.
She captures corrected success rates and confidence intervals using TPR/TNR (from the judge calibration work in lesson 3). The async evals slide shows the 95% confidence intervals - essentially accounting for the fact that your LLM-as-judge isn’t perfect, so you need to adjust your success rate estimates based on the judge’s true positive and true negative rates.

Guardrails
Async evals - it’s okay that they might be imperfect and slow because they’re diagnostic tools. They help you understand your system’s general state and direct your attention to problems. Therefore, they don’t need to be really fast. You don’t need to have really high confidence in them.
However, guardrails are different. They intervene in real-time and direct users to different paths, so they must be fast, reliable, and have very low false positive rates. They’re making actual decisions that affect user experience, not just providing diagnostic information.

Maintaining Judge Accuracy
LLM-as-judge evaluators drift over time. Foundation models change, user behavior evolves, and your team’s quality definitions shift. You need to update your judges accordingly.
You can pin judges to specific model versions, but even then they’ll become outdated unless you’re using open models. For subjective criteria, you should realign your judge every few weeks. Just remember to re-evaluate the judge after updating it to ensure it’s still performing as expected.
Common CD Mistakes
Traditional monitoring tools like Sentry work because they track actual errors. But for AI products, users say “this is rubbish” and disappear forever with no error message to catch. The teams moving fast aren’t using elaborate LLM judges (which often just ask one flawed system to evaluate another flawed system). Instead, they track:
Implicit signals: User frustration markers, task failures, hallucinations
Explicit signals: Regeneration attempts, copy/share rates, thumbs down
Then they cluster these by intent to find where real problems hide.
Additional mistakes:
- Stagnant CI golden datasets: Must be diverse and continuously updated with new phenomena
- Over-reliance on automated monitoring alone: Regular human “failure hunting” is vital for subtle or new issues. Product metrics can be early signals - if engagement changes, do more error analysis
- Delayed or absent re-evaluation of LLM-as-judge alignment: Outdated TPR/TNR leads to inaccurate success rate estimates
- Insufficient traceability: Comprehensive logging is key for debugging
thingsithinkithink
- Shreya’s distinction between constant-output and variable-size output tasks is interesting, but I think she’s identified a symptom rather than the root cause. The real issue is that LLMs aren’t systematic processors. They can’t be exhaustive or thorough out of the box. This matters for any task requiring completeness, regardless of document length.